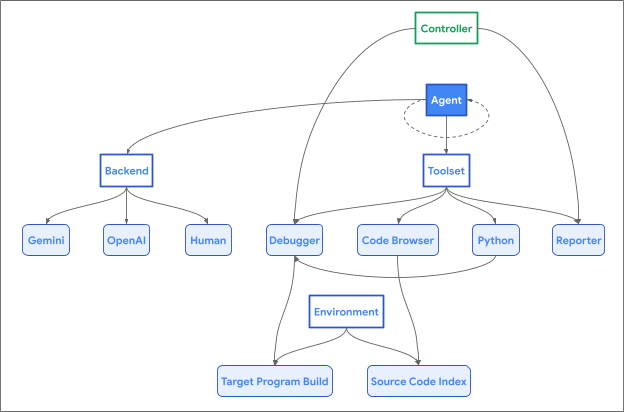
Nagy nyelvi modellek támadó biztonsági képességeinek értékelése
A Project Zero folyamatosan bővíti a sebezhetőségi kutatások hatókörét és hatékonyságát. Bár munkájuk nagy része még mindig olyan hagyományos módszerekre támaszkodik, mint a kézi forráskód-ellenőrzés és a reverse engineering, mindig új megközelítéseket keresnek.
Ahogy a nagyméretű nyelvi modellek (Large Language Models, LLM) kódértési és általános következtetési képességei javultak, azt vizsgálták, hogy ezek a modellek hogyan tudják reprodukálni egy emberi biztonsági kutató szisztematikus megközelítését a biztonsági sebezhetőségek azonosítása és bemutatása során. Remélik, hogy ez a jövőben bezárhatja a jelenlegi automatizált sebezhetőség-felfedezési megközelítések néhány vakfoltját, és lehetővé teszi a kiaknázhatatlan sebezhetőségek automatikus felderítését.
Az LLM-ek sebezhetőségek felderítésére való felhasználásáról szóló meglévő publikációk áttekintésekor azt tapasztalták, hogy számos megközelítés ellentmond az intuíciónknak és tapasztalatoknak. Az elmúlt néhány évben sokat gondolkodtak azon, hogyan használhatnánk az emberi erővel végzett sebezhetőségi kutatásban szerzett szakértelmüket az LLM-ek e feladathoz való hozzáigazításához, és sokat tanultnának arról, hogy mi működik és mi nem működik jól (legalábbis a jelenlegi modellekkel). Bár az emberi munkafolyamat modellezése nem feltétlenül optimális módja annak, hogy egy LLM megoldjon egy feladatot, de a megközelítés megalapozottságának ellenőrzésére szolgál, és lehetővé teszi, hogy a jövőben összehasonlító alapértékeket gyűjtsünk.
Ha megfelelő eszközökkel látják el, a jelenlegi LLM-ek valóban elkezdhetik a sebezhetőségi kutatást (igaz, meglehetősen alapszintű)! Nagy különbség van azonban az elszigetelt CTF-stílusú kihívások kétértelműség nélküli megoldása (mindig van egy hiba, mindig parancssori bemenettel stb.) és autonóm offenzív biztonsági kutatások végrehajtása között. Amint azt már sokszor elmondták, a biztonsági kutatások nagy része a megfelelő helyek megtalálása, és annak megértése (egy nagy és összetett rendszerben), hogy a támadó milyen irányítást gyakorolhat a rendszer állapota felett. Az elszigetelt kihívások nem tükrözik ezeket a bonyolult területeket; ezeknek a kihívásoknak a megoldása közelebb áll a kézi felülvizsgálati munkafolyamat részeként végrehajtott célzott, tartomány-specifikus fuzzing tipikus használatához, mint egy teljesen autonóm kutató.
Ennél is fontosabb, hogy úgy gondolják, hogy azokban a feladatokban, ahol egy szakértő ember az érvelés, a hipotézisalkotás és az érvényesítés több iteratív lépésére támaszkodik, ugyanolyan rugalmasságot kell biztosítani a modellekhez; ellenkező esetben az eredmények nem tükrözik a modellek valós képességszintjét.


