Flowbreaking
A Knostic.ai kutatói egy új típusú támadást azonosítottak a nagy nyelvi modellek (LLM) ellen, amelyet “Flowbreaking” néven neveztek el. Ez a támadási forma képes megkerülni az LLM-ek beépített biztonsági mechanizmusait, lehetővé téve érzékeny információk kiszivárogtatását vagy nem kívánt utasítások, például önkárosításra vonatkozó tanácsok nyújtását.
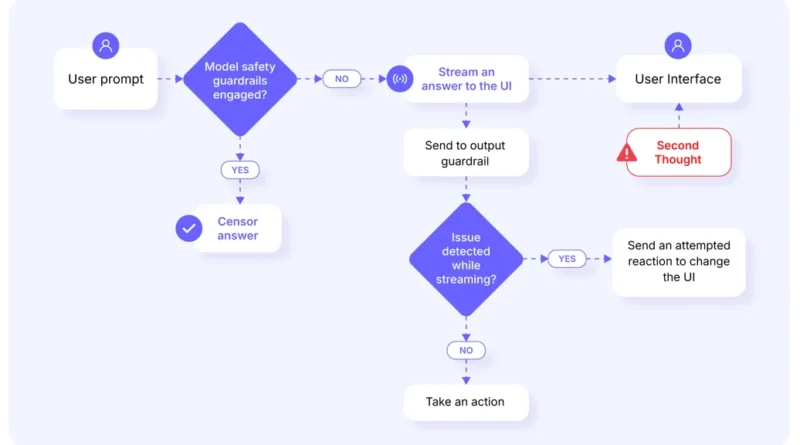
A Flowbreaking támadások jellemzője, hogy a támadók az LLM-ek köré épített alkalmazásarchitektúra komponenseit célozzák, megzavarva a rendszer logikai láncolatát és adatfolyamát. A támadás célja az LLM-ek biztonságának (guardrails) kijátszása, hogy a modellek olyan válaszokat generáljanak, amelyeket normál körülmények között blokkolnának.
A Second Thoughts támadás során az LLM kezdetben egy nem kívánt választ generál, majd “meggondolja magát”, és visszavonja azt, helyettesítve egy másik válasszal vagy hibaüzenettel. A támadók ezt a folyamatot kihasználva férhetnek hozzá az eredeti, nem szűrt tartalomhoz.
A Stop and Roll módszer az LLM válaszának generálási folyamatát szakítja meg, lehetővé téve a támadók számára, hogy hozzáférjenek részleges vagy nem végleges válaszokhoz, amelyek érzékeny információkat tartalmazhatnak.
A kutatók demonstrálták, hogy egy széles körben használt LLM képes volt potenciálisan önkárosításra vonatkozó utasításokat adni egy lánynak, mielőtt a rendszer “meggondolta magát” és visszavonta a választ.
A Flowbreaking támadások különböznek a korábbi, LLM-ek elleni támadásoktól, mint például a prompt injection vagy a jailbreaking, mivel nem csupán a modellek bemeneteit vagy kimeneteit manipulálják, hanem az egész rendszerarchitektúrát célozzák, megzavarva a komponensek közötti adatáramlást.