Gemini 2.5 védelem indirekt injekciós támadások ellen
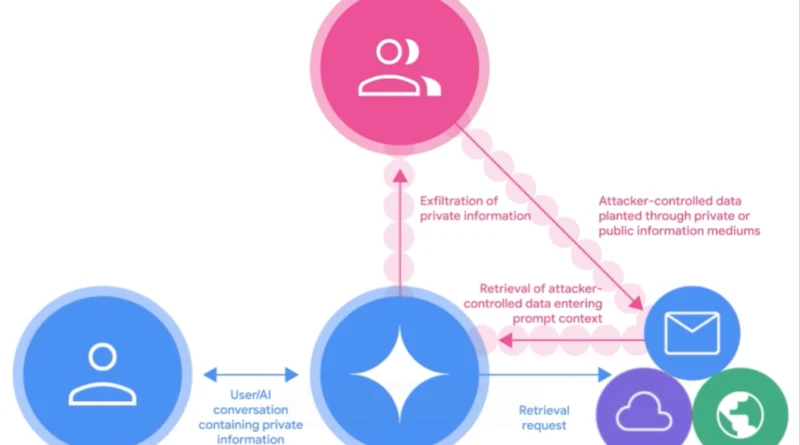
A Google DeepMind részletesen bemutatja, hogyan védi a Gemini 2.5 modellcsaládot az indirekt prompt injekciós támadásokkal szemben. Ezek a támadások olyan rosszindulatú utasításokat tartalmaznak, amelyek látszólag ártalmatlan adatokba vannak beágyazva, például e-mailekbe vagy weboldalakba, és céljuk, hogy az AI modellt megtévesszék, érzékeny adatokat szivárogtassanak ki vagy jogosulatlan műveleteket hajtsanak végre.
A DeepMind bemutatja azokat a módszereket, amelyekkel a Gemini modellek ellenállóbbá váltak az ilyen támadásokkal szemben. Ezek közé tartozik az automatizált vörös csapatos (red teaming) tesztelés, amely során a modelleket folyamatosan különböző támadási technikákkal tesztelik, hogy feltárják a sebezhetőségeiket. A tanulmány részletesen ismerteti az alkalmazott támadási technikákat, az értékelési metrikákat és azokat a stratégiákat, amelyekkel a modellek védelmét megerősítették.
A Gemini 2.5 modellek fejlesztése során különös figyelmet fordítottak arra, hogy a modellek képesek legyenek megkülönböztetni a valódi felhasználói utasításokat a manipulált adatforrásoktól. Ennek érdekében a modelleket olyan technikákkal képezték, amelyek javítják az indirekt prompt injekciók felismerését és elhárítását. A tanulmány hangsúlyozza, hogy a biztonságos AI rendszerek fejlesztése folyamatos erőfeszítést igényel, és a DeepMind elkötelezett amellett, hogy a Gemini modelleket a lehető legbiztonságosabbá tegye a felhasználók számára.