Azure AI védőkorlátok megkerülése
A Mindgard kutatói kritikus sérülékenységeket fedeztek fel a Microsoft Azure AI Content Safety szolgáltatásában, ami lehetővé teszi a rosszindulatú szereplők számára, hogy megkerüljék a biztonsági intézkedéseket, és káros mesterséges intelligencia által generált tartalmakat generáljanak. A brit székhelyű Mindgard startup 2024 februárjában két kritikus biztonsági sérülékenységet fedezett fel a Microsoft Azure AI Content Safety szolgáltatásában. Ezek a hibák lehetővé tehetik a támadók számára, hogy megkerüljék a szolgáltatás biztonsági védőkorlátait. A sérülékenységeket 2024 márciusban közölték a Microsoft-tal, és 2024 októberére a vállalat enyhítéseket telepített a hibák hatása csökkentése érdekében. Ennek részleteit azonban csak most osztotta meg a Mindgard.
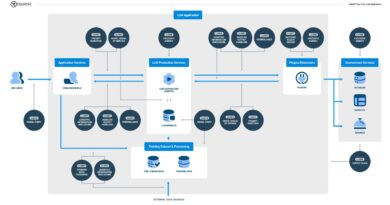
Az Azure AI Content Safety egy Microsoft Azure felhőalapú szolgáltatás, amely a nem megfelelő tartalmak felismerésével és kezelésével segít a fejlesztőknek biztonsági és védelmi intézkedéseket létrehozni a mesterséges intelligencia alkalmazásokhoz. Fejlett technikákat használ a káros tartalmak szűrésére, beleértve a gyűlöletbeszédet és az explicit,elítélendő anyagokat. Az Azure OpenAI a bemenetek és az AI által generált tartalmak validálásához a Prompt Shield és az AI Text Moderation védelmi intézkedésekkel ellátott Large Language Model (LLM) modellt használja.
Két biztonsági résre bukkantak ezekben a védelmi intzékedésekben, amelyek a mesterséges intelligenciamodelleket védik a jailbreak és a prompt injection ellen. A kutatás szerint a támadók megkerülhetik mind az AI Text Moderation, mind a Prompt Shield guardrailt, és káros tartalmakat juttathatnak be a rendszerbe, manipulálhatják a modell válaszait, vagy akár érzékeny információkat is kompromittálhatnak. A Mindgard jelentése szerint a kutatók két elsődleges támadási technikát alkalmaztak a védőkorlátok megkerülésére, köztük a Character injection és az Adversarial Machine Learning-et (AML).