VALL-E szövegfelolvasó
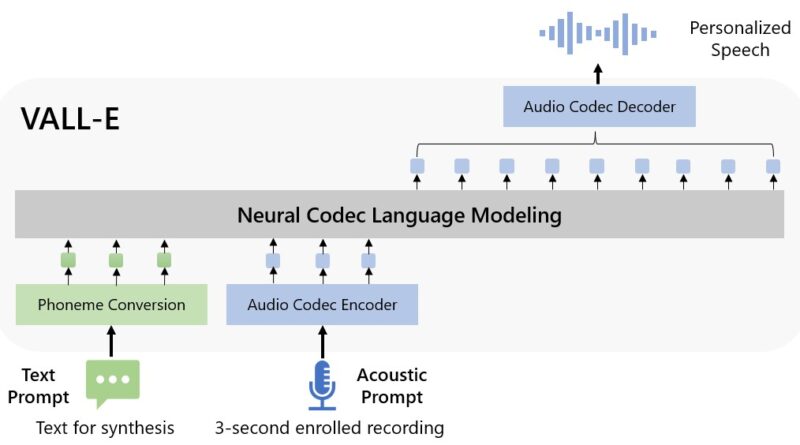
A Microsoft kutatói bejelentették a VALL-E új szövegfelolvasó mesterséges intelligencia-modellt, amely három másodperces hangmintával képes szimulálni egy személy hangját. Amint megtanul egy adott hangot, a VALL-E szintetizálni tudja az adott személy hangját, bármit mondjon – és ezt oly módon teszi, hogy megkísérli megőrizni a beszélő érzelmi tónusát.
A Microsoft a VALL-E-t “neurális kodek nyelvi modellnek” nevezi, és az EnCodec nevű technológiára épül, amelyet a Meta 2022 októberében jelentett be. Más szövegfelolvasó módszerekkel ellentétben, amelyek jellemzően hullámformák manipulálásával szintetizálják a beszédet, a VALL-E diszkrét audiokodek kódok szöveges és akusztikus promptokból. Alapvetően azt elemzi, hogyan hangzik egy személy, ezt az információt az EnCodec-nek köszönhetően diszkrét komponensekre bontja (az úgynevezett “token”-ekre), és a képzési adatokat használja fel arra vonatkozóan, hogy mit “tud” arról, hogyan szólna a hang, ha a három kifejezésen kívül más kifejezéseket mondana.
„Mivel a VALL-E olyan beszédet tud szintetizálni, amely megőrzi a beszélőazonosságot, potenciális kockázatokat rejthet magában a modellel való visszaélés során, mint például a hangazonosítás meghamisítása vagy egy adott beszélőnek való megszemélyesítés. Az ilyen kockázatok mérséklése érdekében fel lehet építeni egy észlelési modellt a megkülönböztetésre. hogy egy hangfelvételt a VALL-E szintetizált-e. A modellek továbbfejlesztése során a Microsoft AI elveit a gyakorlatba is átültetjük.” – jelentette ki a Microsoft.