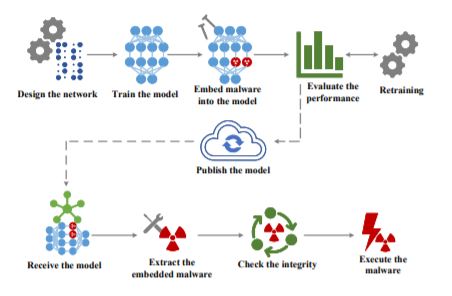
Kártevők a mesterséges intelligencia modellekben
Egy új tanulmány szerint a neurális hálózatok jelenthetik a következő lépcsőfokot a rosszindulatú programok kampányaiban, az egyre elterjedtebb használatuk miatt. Kutatók nem csak elméleti módszerrel bizonyították, hogy képesek elhelyezni kártékony kódokat neutrális hálózati modellekben. Zhi Wang, Chaoge Liu és Xiang Cui által közzétett tanulmány szerint egy 36.9 MB kártékony kódot illesztet be egy 178 MB-os AlexNet neutrális hálózati modellbe.
Az elmúlt években óriási fejlődésen mentek keresztül a neurális hálókkal támogatott képfelismerő alkalmazások, azaz a mesterséges intelligencia felhasználási területének egyike. Rendszeresen megrendezésre kerül az ImageNet verseny, melyen a versenyzők által készített programok a szervezők által megadott képeken próbálják beazonosítani a tárgyakat. 2012-ben ezt az AlexNet nevezetű neurális háló nyerte meg óriási fölénnyel, 16.4%-os Top5 hibával (a neurális háló által legvalószínűbbnek talált öt tárgy egyike se helyes).
A kutatás szerint nem változott a mesterséges intelligencia képessége jelentősen, mindösszesen 1%-al változott a hibahatár. Viszont a kártékony kód keresők nem ismerték fel az elrejtett kódokat, így a VirusTotal sem azonosított semmi gyanúsat a kódokban.
Gyakorlatilag egy szteganográfiai kísérletről szól a kutatás, ami egy technika a kártékony kódok elrejtésére, még nem egy kihasználási módszer, hiszen ahhoz egyéb programokra is szükség van. Viszont az, hogy a neurális hálózati modellekben, mint nagyon nagy méretű és sokrétegű eszközökben elrejthetők ilyen kódok mindenképpen elgondolkodtató. Ugyanakkor az elsődleges visszajelzések szerint ez jelenleg csak azért lehetséges, mert víruskereső eszközök erre még nincsenek optimalizálva, nem itt keresik a kártékony kódokat. Ezt jelezte dr. Lukas Olejnik, a kiberbiztonság kutató a Vice-nak, aki arra is felhívta a figyelmet, hogy a mesterséges intelligenciával támogatott támadások, új kihívásokat jelentenek a jövőben.